Submit functionality enables qualified users to execute certain codes on the compute cluster. In order to use submit functionality, you must have access to the HUBzero Workspace and be a member of the Submit group. These notes describe how to run simple tests of the submit command on the HUBzero instance. All submit commands are run from the HUBzero Workspace command line (alternately, Jupyter Terminal or noVNC terminal).
Contents
- Basic information
- Prerequisites
- Running remote submit
- Debugging and metrics
- Specifying cores and nodes
- Worked examples
- More information
Basic information
For submit usage information and information about configured venues, managers, or tools, type the help command:
$ submit --help venues | managers | tools
Available venues
We have defined several submit venues for general-compute and debug partitions on the CCR cluster. Use "submit --help" to list them, for example:
$ submit --help venues Currently available VENUES are: ccr-ghub ccr-ghub-8cores ccr-ghub-debug ccr-ghub-script submithost u2-grid u2-grid-debug
Specifying the venue in your submit call, with the -v switch, will determine the characteristics of the nodes where your job will be scheduled by the resource manager, Slurm. These parameters are handled behind the scenes in configuration scripts.
The debug partition's nodes have a smaller number of cores per node and a limited walltime (1 hour); these are useful for ensuring the overall soundness of your call; the general-compute nodes (u2-grid and ccr-ghub venues) have up to 40 cores per node and a 72-hour walltime limit.
Refer to CCR cluster documentation for further information about SLURM job scheduler, cluster partitions, and other particulars of the compute cluster.
Choosing a venue
You may not have access to all venues that are listed. If you are running Ghub jobs, please use the ccr-ghub venues (please only use ccr-ghub-8cores if you need extra processing power and only after you have first run using ccr-ghub); legacy Vhub jobs will likely need to use the u2-grid venues.
Default partition processors-per-node
Default cores per node values are set as follows for the submit venues. Consult "Submit parameters" for how to override these cores per node values on the command line.
| submit venue |
cluster partition |
default cores per node |
|---|---|---|
| u2-grid | general-compute | 8 |
| u2-grid-debug | debug | 2 |
| ccr-ghub | general-compute | 8 |
| ccr-ghub-debug | debug | 2 |
Maximum active jobs
This gateway is a shared resource, and all job submissions to the cluster run under a common user. The following maximum active job counts are enforced on submit. Note that your job may be held silently if you have submitted too many!
| submit venue |
cluster partition |
maximum active jobs |
|---|---|---|
| u2-grid | general-compute | 300 |
| u2-grid-debug | debug | 2 |
| ccr-ghub | general-compute | 300 |
| ccr-ghub-debug | debug | 2 |
Prerequisites
In order to use submit functionality, you must have access to the HUBzero Workspace (or the Jupyter Terminal or noVNC terminal) and be a member of the Submit group.
To try out submit functionality, first write a very simple, executable shell script to call for the example below.
Submit will not permit you to execute an arbitrary shell command (such as "ls" or "echo"). If you want to submit arbitrary commands, write them in a shell script and submit the script from your home directory (or a subdirectory thereof).
hello.sh might contain:
#!/bin/sh # hello.sh echo hello
Ensure your script is marked executable:
$ chmod a+x hello.sh $ ls -l hello.sh -rwxrwxrwx 1 jmsperhac public 35 Jan 2 13:29 hello.sh
Ensure your script runs in place as intended:
$ ./hello.sh hello
Running remote submit
First, you can verify that submit is properly configured for a local call. Local calls execute directly on the HUBzero webserver. Ensure you invoke your script in the same way that you did above in 'Prerequisites'. Here we assume that the script hello.sh is in the current directory.
$ submit --debug --local ./hello.sh
Next, test submit on an available venue. This call will submit your job to a venue called "u2-grid" on the CCR compute cluster:
$ submit --debug --venue u2-grid ./hello.sh
Note that the "./" is required for submit to properly execute the script.
As before, invoke your script in the same way that you did above in 'Prerequisites'. Here, the -w parameter requests a job walltime of 10 minutes rather than the default 1 hour. We assume that the script submit_test.sh is in the current directory.
$ submit -v u2-grid -w 10 ./submit_test.sh
Further submit parameters are explained in the HUBzero submit documentation.
Inputs to your job
Some jobs require input files, either data, or source files that must be compiled.
To specify a single input file, use the -i parameter in your submit call and the file will be sent along with your job. For example, to send input.dat as an input file:
$ submit -v u2-grid -i input.dat ./submit_test.sh
To specify more than one input file, omit the -i parameter, and instead list all the files, separated by spaces, after the executable, and they will be available during execution of your job. For example, to send file1.dat, file2.dat, file3.c as inputs:
$ submit -v u2-grid ./submit_test.sh file1.dat file2.dat file3.c
Standard and error output
Submit retrieves any output from your job's run on the cluster back to your home directory on the gateway--you don't need to do anything special to retrieve your output.
For the simple examples described above, submit will create two files, one with file suffix .stdout, and one with .stderr. The file prefix is the submit id of the job (For example, submit id 3918 in the figure below). A file containing the output of the command will be created in your current directory, with the file extension .stdout. If any error is returned, a file containing the error will be created in your current directory, with the file extension .stderr.

For more complex situations, any object files you compile, or output files you generate, will also be returned to your home directory on the gateway when the submit job is complete.
Debugging and metrics
Returning metrics
Use submit's command line option -M to return metrics from a submitted job. See the example figure below.
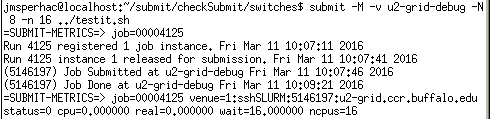
Here, you see information on the exit state of your job (status=0 is success), the submit id (4125) SLURM job number (5146197), and the number of cores (CPUs) it used (16). This is a brief and informative option for your submit job.
Debugging submit
The debug command line option (--debug) displays the protocol, host, and port, and indicates the status of authentication to the cluster machine. It enables you to see the communications between the HUBzero webserver and the cluster machine and track the submission, execution, and completion of the submitted job. It also provides the job number ("Run number").
Here is a successful example with submit id 3785, and slurm id 5026580:

Specifying cores and nodes
When submitting a job to the cluster you may request a total number of cores, and the number of cores per node, that your job needs. Submit will infer from these parameters the total number of nodes to request and place these parameters in the run script it sends to the cluster for execution.
Before you use these parameters, please consult CCR cluster documentation to ensure you are calling for appropriate node and core counts for the partition you are using. Start small, and test on debug first!
Submit parameters
The submit parameters for total core count and cores per node can be specified on the command line.
Total number of cores: n or nCpus
This integer parameter specifies the total number of cores (equivalently, processors, or CPUs) that your job requests. The total number of cores is specified on the submit command line by:
-n
or
--nCpus
See this simple example.
Number of cores per node: N or ppn
This parameter specifies the integer number of cores per node that your job requests. Count of cores in each node is specified on the submit command line by:
-N
or
--ppn
A default number of cores per node is defined for the submit venue. Specifying a ppn value on the command line will override that default. See this simple example.
Total number of nodes
There's no submit parameter for total number of nodes; it's computed from n/N = nCpus/ppn. The default is always 1.
Submit to slurm translation
CCR uses a job scheduler called SLURM; when you prepare a submit script, submit creates a SLURM script that schedules your job on the cluster. Here's how core and node count parameters compare:
| submit param | slurm param | definition |
|---|---|---|
| N | ppn | remotePpn | ntasks-per-node | number of cores per node, for job |
| n | nCpus | total number of cores, for job | |
| n/N | nodes | total number of nodes, for job |
Putting it together
Here's a quick example to show how core count and node count parameters work in submit. Suppose we have a simple shell script called testit.sh. Let's submit it to the cluster just to see how the request works.
Command
The submit command line (requesting N=8 cores per node, n=16 cores in total):
submit -M -v u2-grid-debug -N 8 -n 16 ./testit.sh
equivalently:
submit -M -v u2-grid-debug --ppn 8 --nCpus 16 ./testit.sh
SLURM script and output
The SLURM script prepared by submit contains the following parameters:
#SBATCH --partition debug #SBATCH --nodes=2 #SBATCH --ntasks-per-node=8
SLURM accounting output shows the cores and nodes requested for the job. Here's what SLURM reported for the allocated nodes and CPUs. You can see that submit requested 2 nodes ("AllocNodes"), and 8 cpus per node, for 16 cpus in total ("AllocCPUS"):
JobID Partition AllocNodes NodeList AllocCPUS State ExitCode Start ------------ ---------- ---------- --------------- ---------- ---------- -------- ------------------- 5146197 debug 2 cpn-k08-41... 16 COMPLETED 0:0 2016-03-11T10:07:46
Job output
Output and any error files will be created in the current directory and named after the local submit id, with file suffixes
Submit metrics
Finally, since the call was made with the metrics (-M) parameter, we can see the submit job number (4125), SLURM job number (5146197), successful exit code (0), and number of cores (CPUs) used (16) listed on the command line itself:
More information
For additional information about the submit command, refer to the HUBzero submit documentation.